How AI Search Engines Actually Work: From Prompt to Citation
The full pipeline behind AI search: query fan-out, Reciprocal Rank Fusion, and why only 12% of ChatGPT citations overlap with Google results.

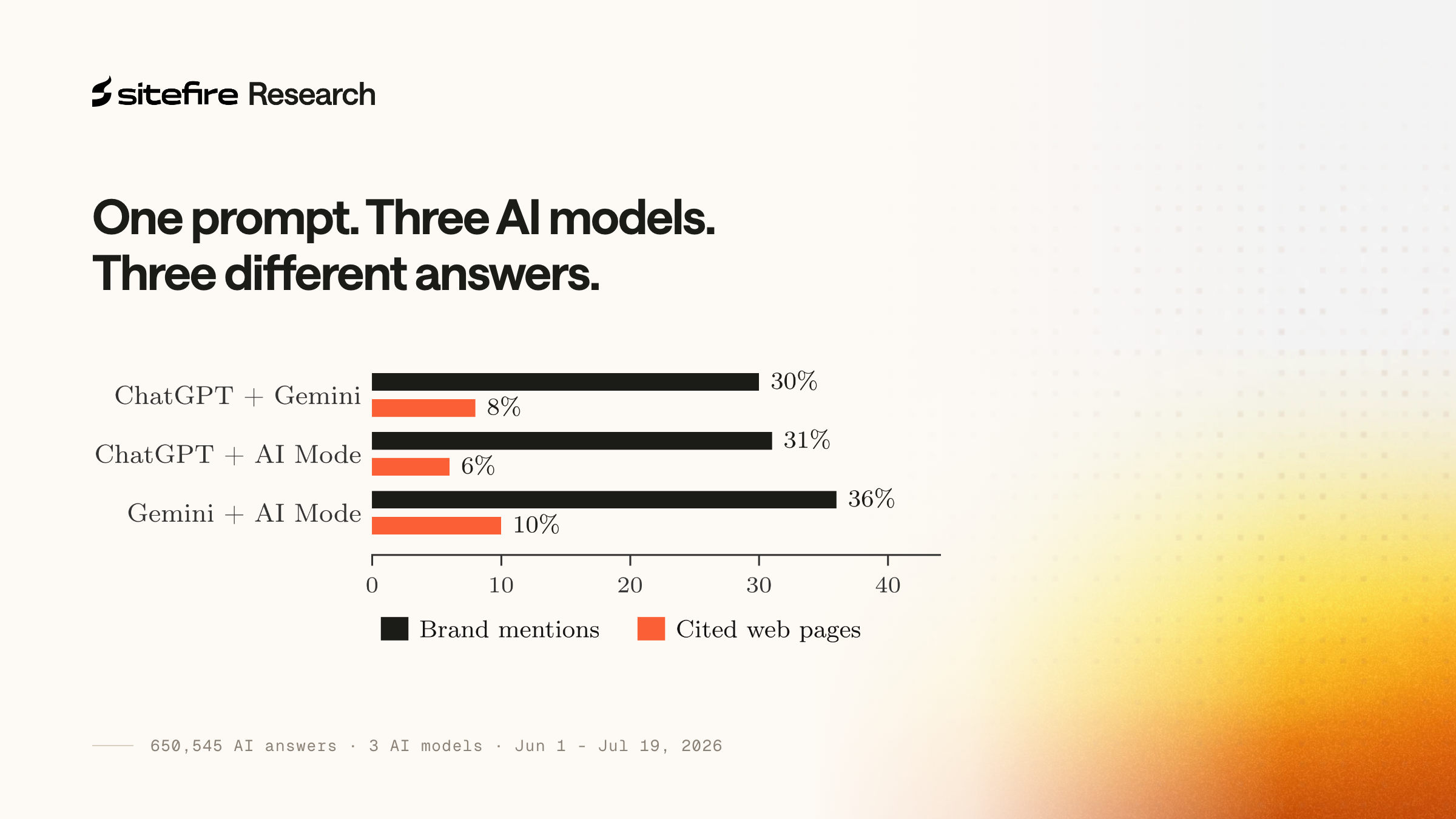
Most GEO advice tells you what to do. Add schema markup. Use data tables. Optimize your headings. But it rarely explains why these tactics work, or what happens between a user typing a question into ChatGPT and your page appearing (or not appearing) as a citation.
The pipeline from prompt to citation has multiple stages, each with its own logic and its own drop-off rate. Content that fails at any stage is invisible. And most marketing teams are optimizing for the wrong stage.
This article maps the full pipeline for the three most important AI search engines: ChatGPT, Google AI Mode, and Perplexity. We explain what they share, where they differ, and what each stage means for your content strategy.
The AI Search Pipeline at a Glance
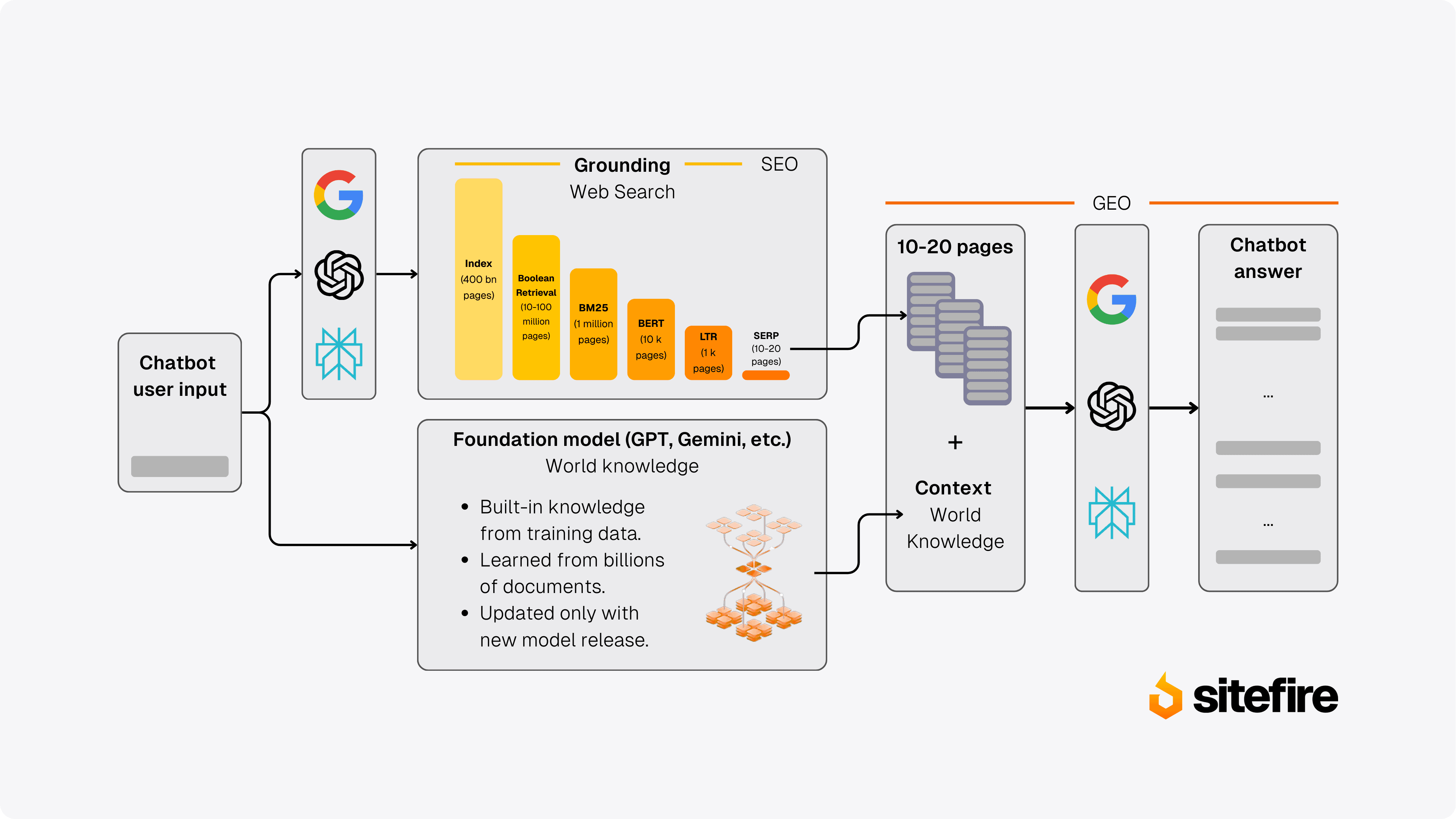
AI search engines follow a variant of Retrieval-Augmented Generation (RAG), an architecture first described by Lewis et al. (2020) that combines real-time information retrieval with language model generation. Every AI search engine uses its own implementation, but the core pipeline is the same.
The pipeline has five stages:
-
Query expansion (fan-out): The AI decomposes the user's prompt into multiple web search queries.
-
Web retrieval: Each sub-query is sent to a search provider (Bing, Google, or a proprietary index) and returns a list of candidate URLs.
-
Source evaluation and merging: Candidate URLs from all query fan-outs are merged into a single ranked list and evaluated for relevance.
-
Answer generation with citations: The AI reads the top-ranked pages, generates an answer, and attaches citations to the sources it used.
-
Brand mention extraction: The AI may or may not mention specific brand names in the answer text, depending on how the source content frames the solution.
Each stage has a conversion drop-off. Not every sub-query finds your page. Not every sourced page gets cited. Not every cited page earns a brand mention in the answer. This pipeline is what we analyze at Sitefire for every prompt we track: where content enters, where it drops out, and why.
How AI Search Engines Expand Your Query
Query fan-out is the process by which an AI search engine generates multiple web search queries from a single user prompt. When a user types "best compliance software for mid-size companies," ChatGPT does not run one search. It generates 5 to 15 query fan-outs, each targeting a different angle of the question.
According to OpenAI's documentation, ChatGPT sends "disassociated search queries" to third-party search providers. These queries are designed to cover the user's intent from multiple directions.
The expansion typically follows three patterns:
Keyword broadening. The AI adds modifiers like "comparison," "evaluate," "in 2026," or "reviews" to make queries more objective and comprehensive. These modifiers are not random. They reflect patterns the model learned during training about how to gather balanced information. A prompt like "best project management tool" might expand into "project management software comparison 2026," "evaluate project management platforms for remote teams," and "project management tool reviews enterprise."
Intent variants. A single prompt generates queries across informational ("what is compliance software"), commercial ("best compliance tools comparison"), and navigational angles ("Drata pricing," "Vanta features"). This means your page competes not just against pages targeting your primary keyword, but against every page that ranks for any of the fan-out variants.
Related entity queries. The AI searches for specific products, competitors, and adjacent concepts mentioned in or implied by the prompt. If a user asks about "CRM software," the AI may generate query fan-outs for Salesforce, HubSpot, and Pipedrive individually, even if the user never named them.
Google takes this further. At Google I/O 2025, Elizabeth Reid described how a custom Gemini 2.5 model decomposes queries into sub-themes. Deep Search, Google's most thorough mode, issues "hundreds of sub-queries" for complex questions.
Perplexity follows a similar approach. According to Perplexity's own research, the platform processes over 200 million daily queries through a multi-stage intent parsing system, retrieving results from an index of over 200 billion URLs.
One critical finding: SurferSEO's study of 173,902 URLs found that only 27% of fan-out queries are stable across repeated searches. The other 73% vary each time. This means your page needs broad topical coverage across a cluster of related queries, not just a single keyword match.
What this means for marketers: Optimizing for one keyword captures one sub-query. Your page needs to rank for the cluster of queries an AI generates from a single prompt.
Where Do the Search Results Come From?
Each AI search engine retrieves web results from a different source. This is why the same page can be cited by one AI and invisible to another.
ChatGPT sends queries to Bing, confirmed by OpenAI's help documentation. Seer Interactive analyzed over 500 citations and found that 87% of ChatGPT citations match Bing's top 10 results. Only 56% match Google's top 10. There is also evidence from Backlinko that ChatGPT may use Google Search in addition to Bing for certain queries.
Google AI Mode uses Google's own search index, processed through Gemini's fan-out system. According to Google Search Central, no special markup is needed. Eligibility comes from the standard Google index.
Perplexity maintains its own index of over 200 billion URLs with a hybrid retrieval system combining lexical and semantic search ( Perplexity Research).
The practical implication: ChatGPT is downstream of Bing rankings. Google AI Mode is downstream of Google rankings. Perplexity has its own ranking system entirely. There is no single search ranking that determines your AI visibility.
How AI Search Engines Merge and Rank Results
Each query fan-out returns approximately 10 results. With 8 query fan-outs, that produces roughly 80 candidate URLs. But only about 25 make it into the final source pool. How does the AI decide which pages to keep?
The answer is Reciprocal Rank Fusion (RRF), an algorithm for merging multiple ranked lists into a single ranking. Cormack, Clarke, and Buettcher published the original paper in 2009 at SIGIR, demonstrating that RRF outperforms individual ranking methods.
The formula is simple. For each query list where the document appears, divide 1 by (k + rank). Then add up all those scores:
RRF_score(document) = 1/(k + rank₁) + 1/(k + rank₂) + ... +1/(k + rankₙ)
The constant k is typically set to 60. This prevents top-ranked items in any single list from dominating the merged result.
Here is a worked example. Suppose three query fan-outs each return three results:
| Document | Rank in Query A | Rank in Query B | Rank in Query C | RRF Score |
|---|---|---|---|---|
| Page X | 1 | - | 3 | 1/61 + 1/63 = 0.0322 |
| Page Y | 2 | 1 | - | 1/62 + 1/61 = 0.0325 |
| Page Z | 3 | - | 2 | 1/63 + 1/62 = 0.0320 |
| Page W | - | 2 | 1 | 1/62 + 1/61 = 0.0325 |
Page Y and Page W tie for the top merged position, even though neither ranked #1 in more than one sub-query. They won because they appeared in multiple lists. Page X, despite ranking #1 in Query A, scores lower because it only appeared in two lists.
RRF is the industry standard for hybrid search. Microsoft Azure AI Search uses it to merge keyword and vector search results. ChatGPT, which retrieves from Bing (a Microsoft product built on Azure), almost certainly uses a variant of RRF.
The co-citation advantage. Pages that appear across multiple sub-query result lists accumulate higher RRF scores. This is why topically comprehensive content outperforms narrow pages. A page that ranks #5 for eight related queries will score higher than a page that ranks #1 for one query and does not appear at all for the others.
The data supports this. SurferSEO's study found a Spearman correlation of 0.77 between fan-out coverage (ranking for multiple query fan-outs) and AI Overview citations. Pages ranking across multiple fan-out queries saw a 161% citation lift compared to pages ranking for only one.
Why Google Rankings Don't Predict AI Citations
If you rank #1 on Google, you should show up in AI answers. Right?
Not necessarily. Ahrefs tested 15,000 long-tail queries across ChatGPT, Gemini, Copilot, and Perplexity, comparing cited URLs against Google and Bing top-10 results. Their finding: only 12% of AI-cited URLs appear in Google's top 10 for the original prompt. For ChatGPT, Gemini, and Copilot specifically, overlap hovers around 8%. And 80% of those citations do not rank anywhere in Google for the original query.
Why such a large gap? Four reasons:
-
Different search provider. ChatGPT retrieves from Bing, not Google. Rankings differ between the two.
-
Different query expansion. ChatGPT generates different query fan-outs than what a human types into Google.
-
Different merging logic. RRF-based merging rewards breadth across query fan-outs, not just rank position.
-
Snippet evaluation. The AI model evaluates page content (meta descriptions, structured data, leading paragraphs) differently than Google's ranking algorithm.
The SurferSEO study corroborates this: 68% of AI Overview-cited pages fall outside the traditional Google top 10 ( SurferSEO).
Takeaway: Google ranking is necessary for visibility in Google AI Mode and partially relevant for ChatGPT (via Bing correlation). But it is not sufficient. A page ranking #8 can outperform a page ranking #1 if it covers more query fan-outs and provides more structured, extractable content.
What Makes an AI Choose Your Page as a Citation?
AI search engines select citations based on content structure, freshness, domain authority, specificity, and how directly the page answers the sub-query. The AI reads snippets (meta descriptions, structured data, leading paragraphs) and decides which pages to read in full and reference in the answer.
Content structure. Clear headings, data tables, and FAQ markup make content easier for AI models to extract and cite. The original GEO research by Aggarwal et al. (2024), published at KDD, found that structured content optimizations can improve visibility by up to 40%.
Freshness. Content updated recently gets cited more frequently. You can check when your page was last crawled at index.commoncrawl.org.
Harmonic Centrality and PageRank. CommonCrawl uses Harmonic Centrality (HC) to prioritize which pages to crawl. Pages with higher HC are crawled more often and appear more frequently in the datasets used to train AI models. According to a Mozilla Foundation study, 64% of 47 analyzed AI models use filtered CommonCrawl data. GPT-3 used CommonCrawl for over 80% of its training tokens.
Specificity. Pages that directly answer the sub-query with concrete data, numbers, and examples outperform generic overviews. The AI is looking for extractable answers, not vague summaries.
Page speed. Faster pages are more likely to be fully crawled and indexed by both traditional search engines and AI crawlers.
Training Data vs. Real-Time Search
There are two sources of AI "knowledge." The first is what the AI model learned during training (offline knowledge). The second is what it retrieves via web search in real time (online knowledge). The RAG architecture, first described by Lewis et al. (2020), combines both.
Training data influence is real. CommonCrawl's Harmonic Centrality determines crawl frequency, which determines how often a page appears in training data. Pages with high HC get crawled more often and are overrepresented in the datasets that train AI models. But AI models deduplicate training data during preprocessing, so raw crawl frequency does not directly translate to influence.
You can check your domain's Harmonic Centrality ranking at CommonCrawl's web graph statistics page. High-HC domains like Wikipedia, GitHub, and major news sites appear near the top. If your domain has low HC, it may be underrepresented in training data, which affects "offline" visibility.
When web search is active (the default for most AI search scenarios), real-time retrieval dominates. Training data provides a baseline understanding of topics and entities, but fresh web results override it for specific queries. According to Semrush's 2025 study, approximately 16% of Google queries trigger AI Overviews, and the rate for commercial queries has risen from 8% to 19%. Most of these involve real-time retrieval.
What this means for marketers: For competitive commercial queries where the AI does web search, your current content quality matters more than your historical web presence. But for queries where AI answers from memory (simple factual questions, well-established topics), training data representation is decisive. At Sitefire, we track both dimensions: which pages get cited in real-time AI search, and which brands the AI already "knows" from training.
How Each AI Search Engine Differs
Not all AI search engines are the same. The following table compares the three most important platforms across the dimensions that matter for content optimization.
| Feature | ChatGPT | Google AI Mode | Perplexity |
|---|---|---|---|
| Search provider | Bing (+ possibly Google) | Google's own index | Own index (200B+ URLs) |
| Fan-out scope | 5-15 query fan-outs | Hundreds (Deep Search) | Multi-stage intent parsing |
| Merging logic | RRF-like (via Bing/Azure) | Gemini-native ranking | Lexical + semantic hybrid |
| Citation style | Inline numbered footnotes | Inline with source cards | Inline numbered with previews |
| Content preference | Institutional authority (Wikipedia, Forbes) | E-E-A-T signals, Google ranking factors | User-generated content (Reddit, YouTube) |
These preferences are confirmed by large-scale citation studies. Ahrefs analyzed 78.6 million AI interactions and found that Wikipedia accounts for 16.3% of ChatGPT mentions, while YouTube dominates Perplexity at 16.1%, and Reddit (7.4%) and Quora (3.6%) rank high in Google AI Overviews. BrightEdge's AI search study corroborates this: ChatGPT skews toward retailer and institutional content (41.3% of citations), while Google AI Overviews favor social and community content (12.3%, led by YouTube at 62.4%).
The differences go deeper than content preference. ChatGPT generates 5 to 15 query fan-outs and merges them via RRF through Bing's infrastructure. Google's Deep Search issues hundreds of query fan-outs through its own index with Gemini-native ranking. Perplexity runs multi-stage intent parsing against its proprietary 200 billion-URL index using a hybrid lexical-semantic retrieval system.
Even citation presentation differs. ChatGPT uses numbered footnotes. Google AI Mode shows source cards with page titles and favicons. Perplexity provides inline numbered citations with hover previews. Each format shapes how users interact with sources, which affects click-through behavior.
The result: a page cited by ChatGPT may not be cited by Perplexity, and vice versa. This is why Sitefire monitors AI visibility across every major model. Optimizing for one platform based on assumptions about another is a common and costly mistake.
For context on the relative size of these platforms: according to Sitefire's January 2026 market share analysis, ChatGPT accounts for 56% of global AI search sessions, while Google's AI ecosystem (AI Mode + Gemini) captures 35%. Perplexity, Claude, and others split the remaining share. But market share alone does not determine which platform matters for your business. A niche B2B product might see disproportionate queries on Perplexity (which skews toward technical and research-oriented users), while a consumer brand sees most of its AI exposure in Google AI Mode.
From Cited to Mentioned: The Last Drop-Off
Being cited and being mentioned are not the same thing. A citation means your URL appears in the footnotes or source list. A mention means your brand name appears in the answer text itself. The distinction matters because users read the answer, not the footnotes.
A page can be sourced and cited as a reference without the brand ever appearing in the answer. This happens when the AI extracts factual information from your page (a statistic, a definition, a comparison) but does not frame the information as a brand recommendation.
What drives brand mentions:
-
Explicit brand positioning in the content. If your page says "Acme solves X by doing Y," the AI has a clear entity to mention. If the page says "the best approach to X is Y" without naming a brand, the AI cites the page but mentions no one. The content must give the AI model a named entity to attach to the solution.
-
Reviews and comparisons. Pages that name brands as solutions to specific problems give the AI a natural entity to surface. Comparison posts, "best of" lists, and review aggregators are among the highest-mention-rate content types because they explicitly map brands to use cases.
-
Third-party validation. When review sites, industry publications, and forums mention your brand in connection with a problem, the AI aggregates those signals across multiple sources. A brand mentioned on three independent pages is more likely to appear in the answer than one mentioned only on its own website.
-
Structured product information. Clear product descriptions with named features, pricing tiers, and differentiation statements give the AI extractable attributes to include in the answer. Vague positioning ("we help companies succeed") gives the AI nothing to work with.
What this means for marketers: Generic educational content earns citations. Branded content earns mentions. To be mentioned (not just cited), your content must explicitly name your brand in connection with the solution. And that signal must be reinforced by third-party sources that also name your brand. This is why Sitefire analyzes the full funnel: sourced pages, cited pages, and brand mentions, each separately.
Frequently Asked Questions
Does Google ranking still matter for AI visibility?
Yes, but it is not enough. Google AI Mode uses Google's index directly, and 87% of ChatGPT citations match Bing's top 10, which correlates with Google. However, 68% of AI Overview-cited pages fall outside the traditional Google top 10. Ranking helps you get sourced, but topical breadth across fan-out queries determines whether you get cited.
How many query fan-outs does ChatGPT generate per prompt?
Typically 5 to 15 for standard queries. Google's Deep Search generates hundreds. The exact number depends on prompt complexity, but even simple commercial queries produce multiple query fan-outs targeting different angles of the question.
Can you see which queries ChatGPT generates from your prompt?
Yes. Open your browser's DevTools, go to the Network tab, and search for your chat ID (from the URL bar). Look for search_model_queries in the response payload. This reveals the exact query fan-outs ChatGPT used to search the web. You can also find the snippet field to see how ChatGPT summarized each search result, and the classifier_snapshot_id to determine when OpenAI last indexed the page.
Is it better to optimize for ChatGPT or Google AI Mode?
Both matter, but they use different retrieval pipelines. ChatGPT pulls from Bing. Google AI Mode pulls from Google's own index. Perplexity uses its own 200 billion-URL index. A multi-platform strategy is necessary because visibility on one does not guarantee visibility on the others.
Does being in AI model training data help with AI search visibility?
For queries where the AI model answers from memory (no web search), yes. Training data representation, influenced by CommonCrawl's Harmonic Centrality, determines what the model "knows." But for most commercial queries, real-time web retrieval dominates ( Lewis et al., 2020). Current content quality matters more than historical web presence.
Key Takeaways
-
AI search engines do not run one search. They expand your prompt into 5 to 15+ query fan-outs, retrieve results from multiple sources, and merge them using algorithms like Reciprocal Rank Fusion (RRF).
-
Only 12% of ChatGPT's cited pages overlap with Google's top results. Google ranking is necessary but far from sufficient for AI visibility.
-
The pipeline has three conversion points: sourced, cited, and mentioned. Each stage has a drop-off, and optimizing for one stage alone leaves value on the table.
-
Pages that appear across multiple query fan-outs accumulate higher RRF scores. Topical breadth beats single-keyword dominance, with a 161% citation lift for pages ranking across multiple queries.
-
Each AI search engine uses a different pipeline. ChatGPT relies on Bing, Google AI Mode on its own index, and Perplexity on its own 200B+ URL index.
-
To earn brand mentions (not just citations), your content must explicitly name your brand in connection with the solution, reinforced by third-party sources.
The shift from "rank on Google" to "get cited by AI" requires understanding a fundamentally different pipeline. The mechanics are more complex, the signals are different, and the competitive dynamics are still forming. But the companies that understand how the pipeline works have a structural advantage over those still optimizing for a single search engine.
Sources
Primary Sources
-
Cormack, G., Clarke, C., & Buettcher, S. "Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods." SIGIR 2009. https://cormack.uwaterloo.ca/cormacksigir09-rrf.pdf
-
Microsoft. "Hybrid Search Scoring (RRF) - Azure AI Search." https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking
-
OpenAI. "ChatGPT search." Help Center. https://help.openai.com/en/articles/9237897-chatgpt-search
-
Google. "AI Mode in Google Search: Updates from Google I/O 2025." https://blog.google/products/search/google-search-ai-mode-update/
-
Google. "AI Features and Your Website." Search Central. https://developers.google.com/search/docs/appearance/ai-features
-
Lewis, P., et al. "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." NeurIPS 2020. https://arxiv.org/abs/2005.11401
-
Perplexity. "Architecting and Evaluating an AI-First Search API." https://research.perplexity.ai/articles/architecting-and-evaluating-an-ai-first-search-api
-
CommonCrawl. "Web Graph Statistics." https://commoncrawl.github.io/cc-webgraph-statistics/
Secondary Sources
-
Stox, P. "AI Search Overlap: How Much Do AI Citations Match Google's Top 10?" Ahrefs. 2025. https://ahrefs.com/blog/ai-search-overlap/
-
Stox, P. "Top 10 Most Cited Domains by AI Assistants." Ahrefs. 2025. https://ahrefs.com/blog/top-10-most-cited-domains-ai-assistants/
-
BrightEdge. "How Different AI Search Engines Choose Which Brands to Recommend." 2025. https://www.brightedge.com/resources/weekly-ai-search-insights/how-different-ai-search-engines-choose-which-brands-to-recommend
-
Seer Interactive. "87% of SearchGPT Citations Match Bing's Top Results." 2025. https://www.seerinteractive.com/insights/87-percent-of-searchgpt-citations-match-bings-top-results
-
Mozilla Foundation. "Training Data for the Price of a Sandwich: Common Crawl's Impact on Generative AI." 2024. https://www.mozillafoundation.org/en/research/library/generative-ai-training-data/common-crawl/
-
SurferSEO. "Ranking for Multiple Fan-Out Queries Dramatically Increases Your Chances of Getting Cited in AIOs." 2025. https://surferseo.com/blog/query-fan-out-impact/
-
Semrush. "AI Overviews Study: What 2025 SEO Data Tells Us." 2025. https://www.semrush.com/blog/semrush-ai-overviews-study/
-
Aggarwal, P., et al. "GEO: Generative Engine Optimization." KDD 2024. https://arxiv.org/abs/2311.09735
-
Backlinko. "ChatGPT Is Using Google Search — We Tested It." 2025. https://backlinko.com/chatgpt-using-google-search
-
sitefire. "Global AI Search Engine Market Share." January 2026. https://sitefire.ai/blog/model-market-share-jan-2026